From Inpainting to Layer Decomposition:
Repurposing Generative Inpainting Models for Image Layer Decomposition
* This work was done when Jingxi Chen was an applied scientist intern at Amazon Prime Video team.
 arXiv
arXiv
Abstract
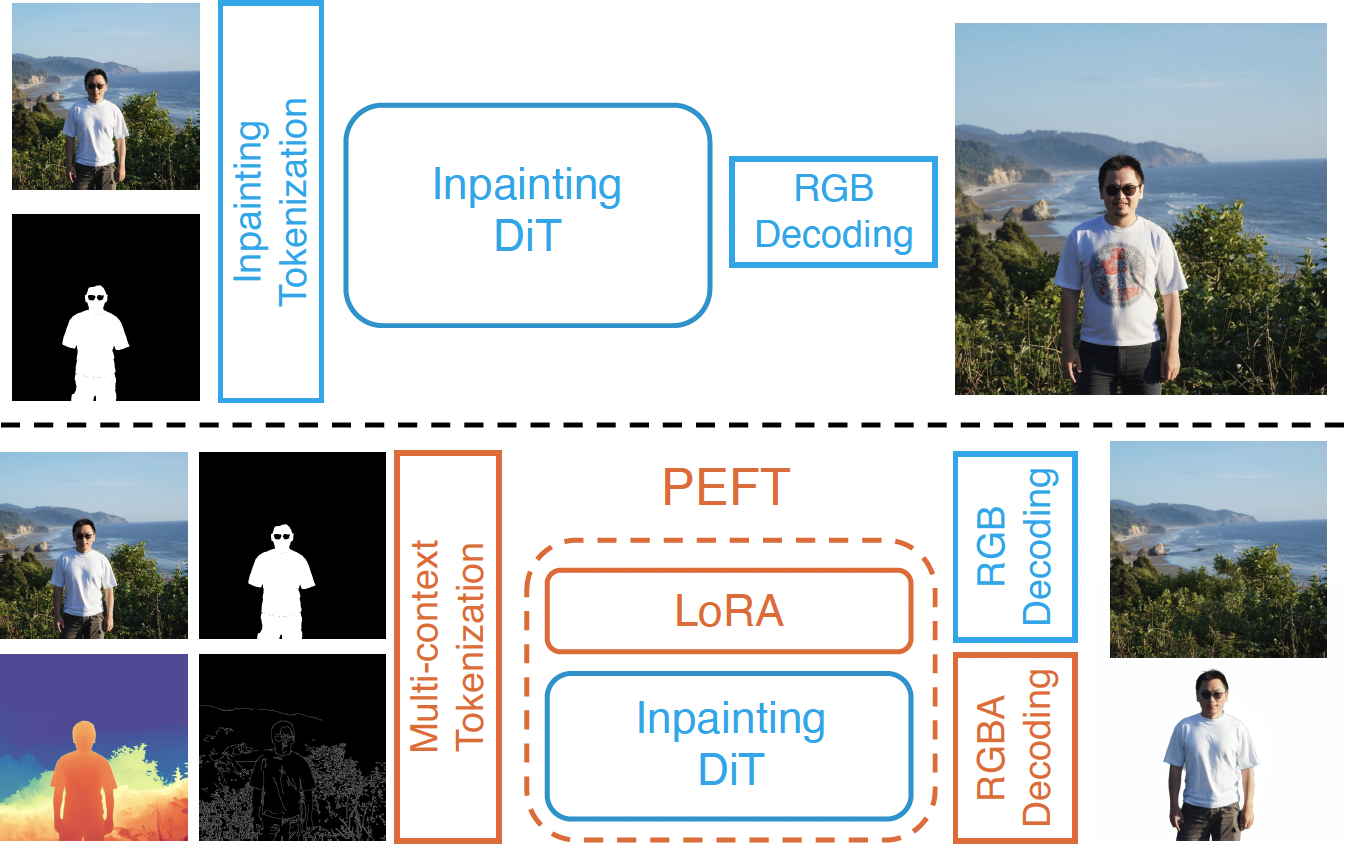
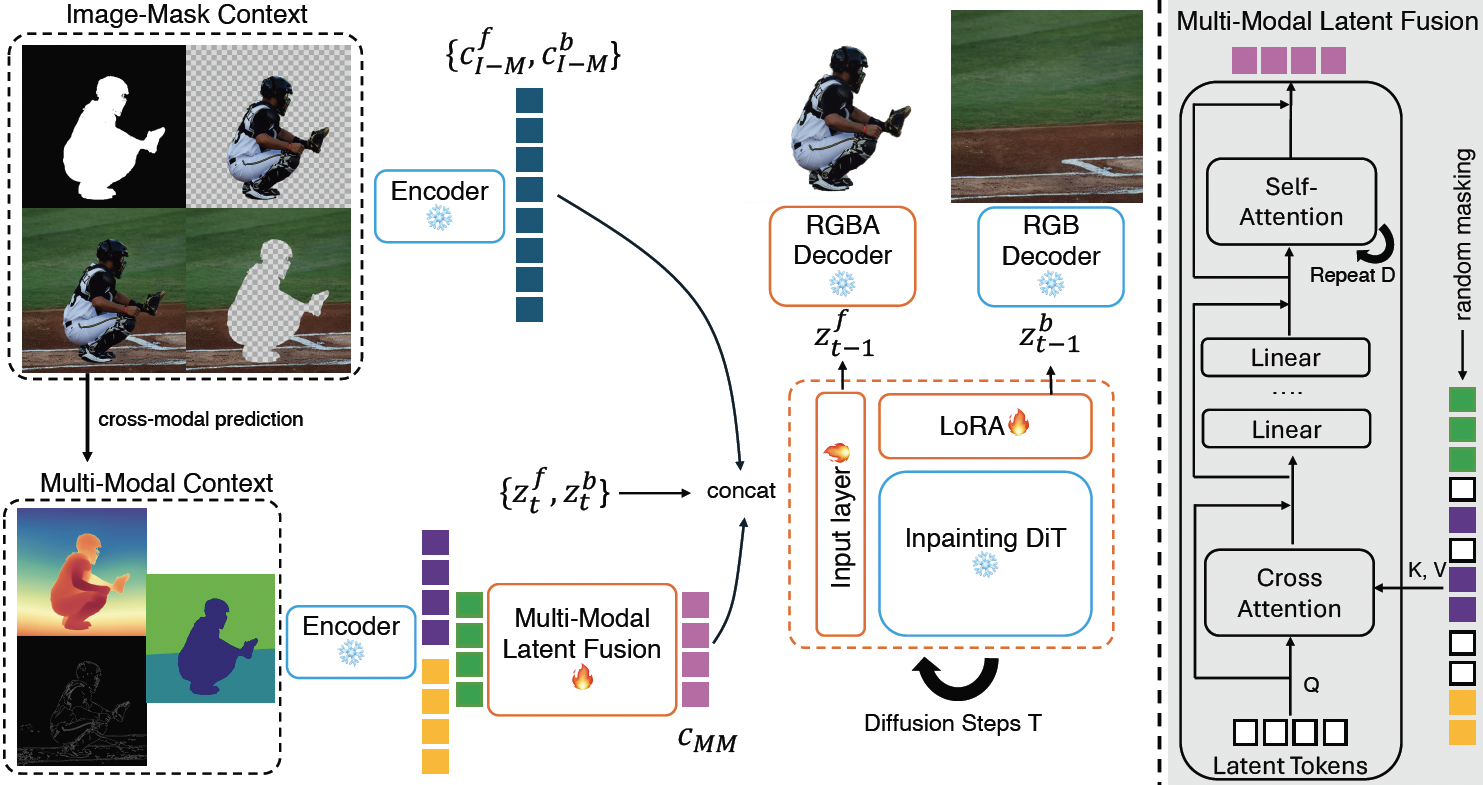
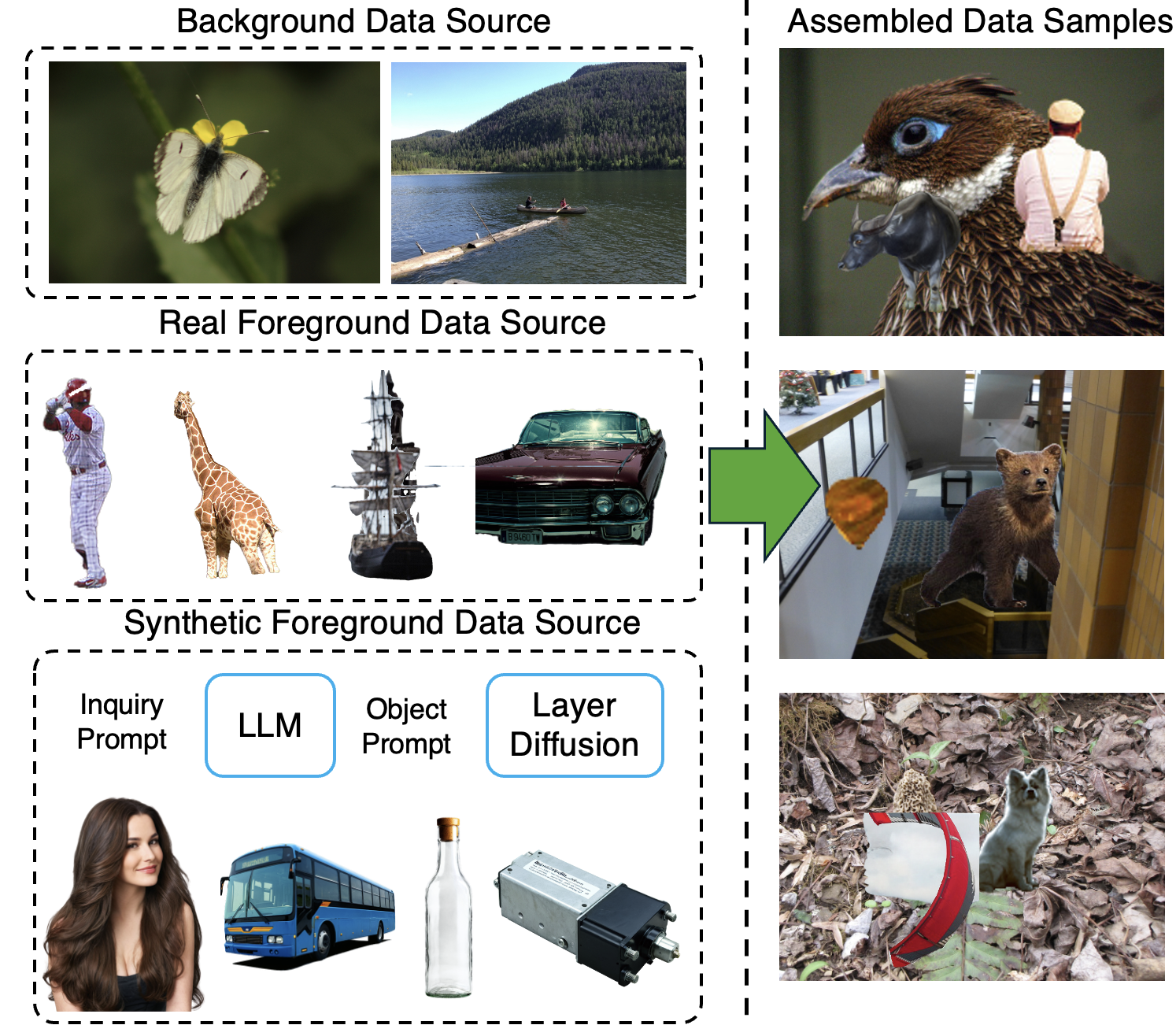
Images can be viewed as layered compositions, foreground objects over background, with potential occlusions. This layered representation enables independent editing of elements, offering greater flexibility for content creation. Despite the progress in large generative models, decomposing a single image into layers remains challenging due to limited methods and data. We observe a strong connection between layer decomposition and in/outpainting tasks, and propose adapting a diffusion-based inpainting model for layer decomposition using lightweight finetuning. To further preserve detail in the latent space, we introduce a novel multi-modal context fusion module with linear attention complexity. Our model is trained purely on a synthetic dataset constructed from open-source assets and achieves superior performance in object removal and occlusion recovery, unlocking new possibilities in downstream editing and creative applications.


ACKNOWLEDGMENT
We acknowlege and appreciate the inspiration of prior work in the generative image layer decomposition, especially the work of Generative Image Layer Decomposition with Visual Effects by Jinrui Yang et al., which has significantly influenced our research direction and methodology. We also thank the open-source community for providing valuable resources and datasets that have facilitated our research.